딥러닝
강사: 이숙번님
1. Hidden Layer(은닉층)
: 입력 데이터를 다양한 방식으로 가공하고 변경해서 의미를 만들어내는 역활
- 입력과 출력 사이에 있는 중간 단계
- 단순한 입력/출력만으로는 풀 수 없는 복잡한 문제를 해결하기 위해 필요함.
- 데이터를 가공하고, 중요한 특징을 추출하며, 비선형 관계를 학습할 수 있도록 하기 위해 필요함.
- 결과적으로 더 정확하고 유연한 모델을 만들기 위해 은닉층이 필요함.

Hidden Layer - 5개의 특징(특징 자동 추출기)
예시: 고양이 사진 인식
- 입력: 픽셀 데이터 (이미지의 숫자 값들)
- 은닉층 역할:
- 1번째 은닉층: "이 부분은 선처럼 보인다"를 학습.
- 2번째 은닉층: "여기에는 둥근 모양이 있다"를 학습.
- 3번째 은닉층: "귀, 눈, 코의 위치가 고양이처럼 보인다"를 학습.
- 출력: "이건 고양이다."
이처럼 단순한 데이터에서부터 점점 복잡한 특징을 자동으로 뽑아내는 과정이 은닉층을 통해 이루어집니다.
import pandas as pd
import tensorflow as tf
url = 'https://raw.githubusercontent.com/blackdew/tensorflow1/refs/heads/master/csv/iris.csv'
df = pd.read_csv(url)
df_onehot = pd.get_dummies(df)
print(df_onehot.columns)
x_train = df_onehot[['꽃잎길이', '꽃잎폭', '꽃받침길이', '꽃받침폭']]
y_train = df_onehot[['품종_setosa', '품종_versicolor', '품종_virginica']]
print(x_train.shape, y_train.shape)
X = tf.keras.Input(shape=[4])
H = tf.keras.layers.Dense(8, activation="relu")(X) # Hidden layer 추가
H = tf.keras.layers.Dense(8, activation="relu")(H) # Hidden layer 추가
H = tf.keras.layers.Dense(8, activation="relu")(H) # Hidden layer 추가
Y = tf.keras.layers.Dense(3, activation="softmax")(H)
model = tf.keras.Model(X, Y)
model.compile(loss="categorical_crossentropy", metrics=["accuracy"])
model.summary()
- metrics 추가
model.compile(loss="mse", metrics=[tf.keras.metrics.R2Score()])
model.compile(loss="categorical_crossentropy", metrics=["accuracy", tf.keras.metrics.AUC])
2. 이미지 학습

2.1. 딥러닝 - 손글씨 분류 모델
import tensorflow as tf
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
print(x_train.shape, y_train.shape)
print(x_test.shape, y_test.shape)
# 결과
(60000, 28, 28) (60000,)
(10000, 28, 28) (10000,)
import matplotlib.pyplot as plt
print("정답: ", y_train[1])
plt.imshow(x_train[0], cmap='gray')
plt.show()
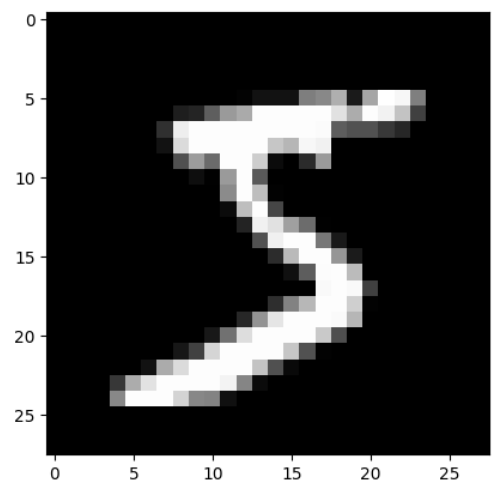
import pandas as pd
pd.set_option('display.max_columns', None)
pd.DataFrame(x_train[1])
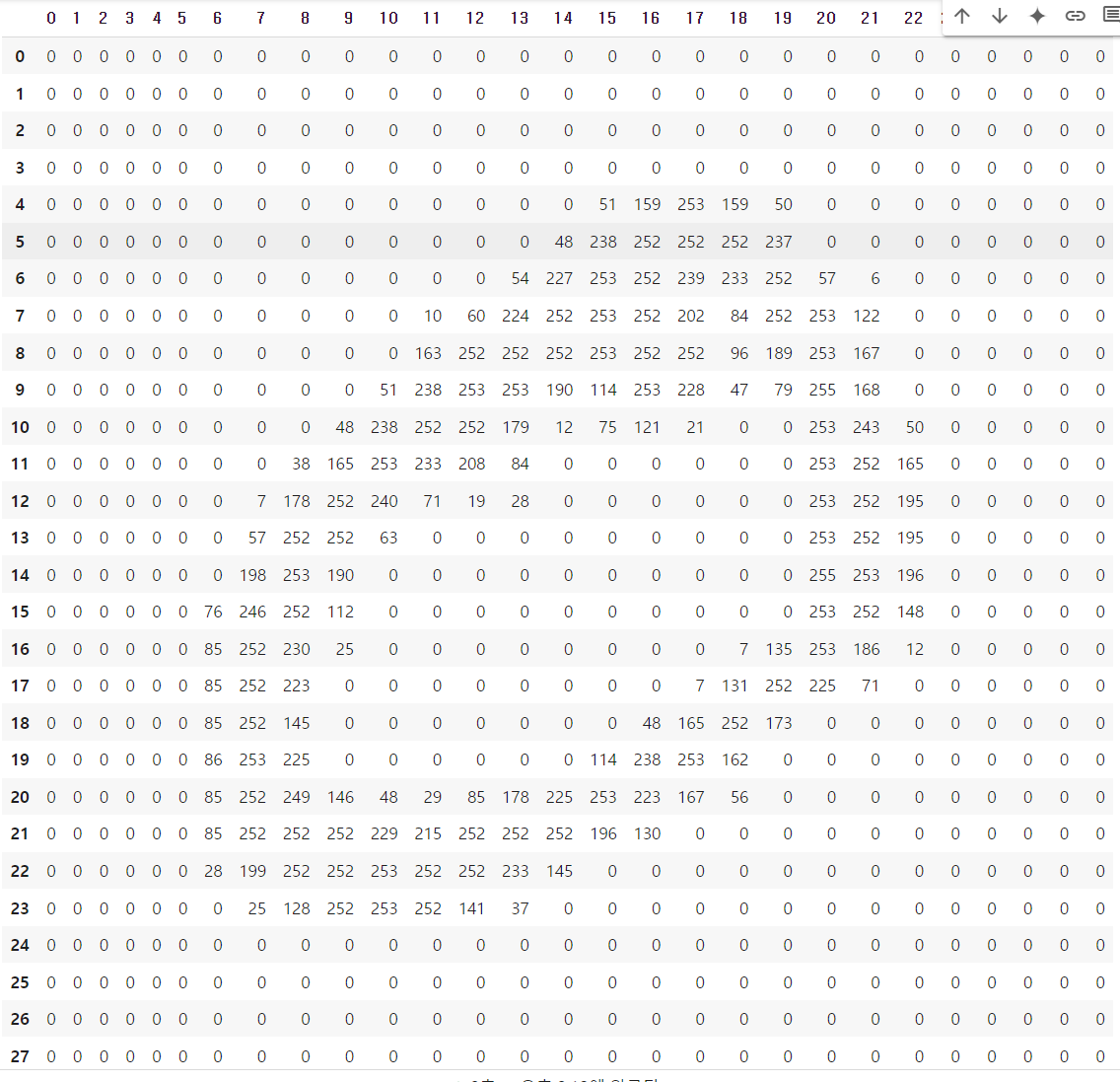
- reshape를 사용하여 한 줄의 표의 형태로 만듬.

- reshape 사용
import numpy as np
a = np.array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
print(a.shape)
a = np.array([[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]])
print(a.shape)
a = np.array([[0], [1], [2], [3], [4], [5], [6], [7], [8], [9], [10], [11]])
print(a.shape)
a = np.array(
[
[0, 1],
[2, 3],
[4, 5],
[6, 7],
[8, 9],
[10, 11]
]
)
print(a.shape)
# 결과
(12,)
(1, 12)
(12, 1)
(6, 2)
a = a.reshape(3, 2, 2) # 2행 2열 3개
print(a)
a = a.reshape(2, 3, 2) # 3행 2열 2개
print(a)
# 결과
[[[ 0 1]
[ 2 3]]
[[ 4 5]
[ 6 7]]
[[ 8 9]
[10 11]]]
[[[ 0 1]
[ 2 3]
[ 4 5]]
[[ 6 7]
[ 8 9]
[10 11]]]
import tensorflow as tf
import pandas as pd
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
print(x_train.shape, y_train.shape)
print(x_test.shape, y_test.shape)
x_train = x_train.reshape(60000, 784)
# y_train = pd.get_dummies(y_train)
y_train = tf.keras.utils.to_categorical(y_train) # 텐서플로우의 원핫인코딩 함수
print(x_train.shape, y_train.shape)
# 결과
(60000, 28, 28) (60000,)
(10000, 28, 28) (10000,)
(60000, 784) (60000, 10)
- 원래 y_train은 숫자 레이블(0, 1, 2, ..., 9)로 되어 있음.
- 숫자 레이블을 바로 처리하지 못하기 때문에 원핫인코딩으로 변환해야함.
pd.DataFrame(y_train)

X = tf.keras.Input(shape=[784])
Y = tf.keras.layers.Dense(10, activation='softmax')(X)
model = tf.keras.Model(X, Y)
model.compile(loss='categorical_crossentropy', metrics=['accuracy'])
model.fit(x_train, y_train, epochs=10)
3. Linear Regression, Logistic Regression
3.1. Linear Regression(선형 회귀)

3.2. Logistic Regression(로지스틱 회귀)

- 최적의 그래프를 찾는 방법
a. 모델 결과와 각 데이터의 오차를 구한다.
b. 오차를 모두 더한다.
c. 오차의 합이 최소가 되게 한다.
3.3. 선형회귀와 최소제곱 추정

3.4. 선형회귀와 최소제곱합
- SST: Y의 평균값으로 설명할 수 없는 분산
- SSR: SST 중 선형회귀식을 통해 얼마나 설명해낸 분산
- SSE: 선형회귀식이 설명할 수 없는 분산
3.5. 로지스틱 회귀와 크로스 엔트로피


- 크로스 엔트로피(Cross Entropy)는 분류 문제에서 모델의 예측이 얼마나 정확한지 평가하기 위해 사용하는 손실 함수(loss function)입니다.
- 모델의 예측 확률이 실제 정답과 얼마나 가까운지를 측정.
- 크로스 엔트로피 공식

- : 클래스 개수 (예: 고양이, 강아지, 새 → C=)
- yi: 실제 정답 (One-Hot Encoding으로 표현, 정답 클래스는 1, 나머지는 0)
- : 모델이 예측한 확률 값
- 예시

3.6. Perceptron

3.7. 인공신경망
: Perceptron이 모여 Layer를 이루는 것

-> X와 Y사이에 특정 함수가 존재 한다면, Multi Layer는 인공신경망이 어떤 함수든 근사(Approximate)할 수 있다.
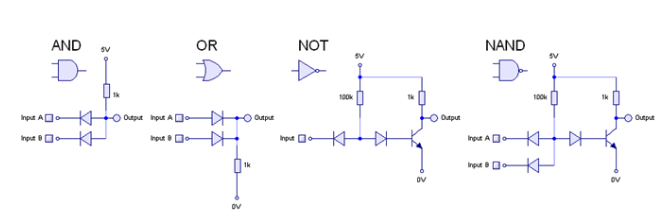
3.8. Computer
- 컴퓨터는 논리 Gate들의 연결을 통해 구성
- Not, And, Or Gate를 쌓아 연산을 만듬
- Nand Gate를 쌓아 Not, And, Or Gate를 만듬.
- Nand만으로 컴퓨터를 완성할 수 있음.
- Nand Gate는 Universal Gate라고도 불림.
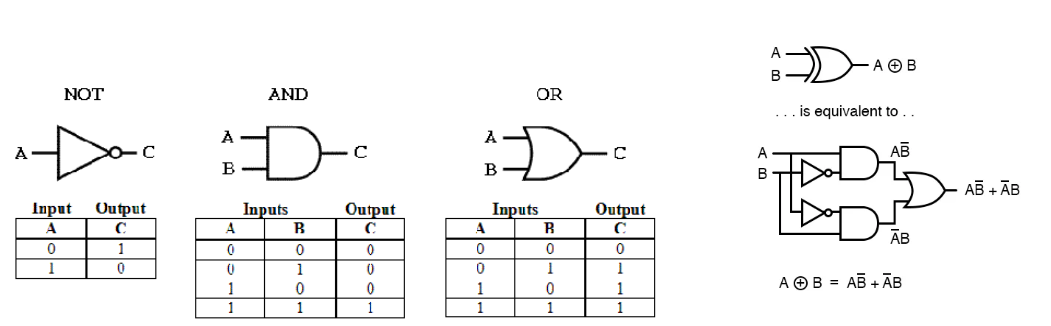


4. Optimizer

- GD(Gradient Descent, 경사하강법)
: 함수의 기울기(경사)를 구하여 함수의 극값에 이를 때까지 기울기가 낮은 쪽으로 반복하여 이동하는 방법

- 알파 값은 learning rate이다.
- Momentum(관성)
: 이전에 이동했던 방향을 기억해서 다음 이동의 방향에 반영
- Adagrad(Adaptive Gradient)
: 많이 이동한 변수(w)는 최적값에 근접했을 것이라는 가정하에, 많이 이동한 변수(w)를 기억해서 다음 이동의 거리를 줄인다.
- Adam(RMSprop + Momentum)
: Adagrad 업그레이드인 RMSprop와 Momentum을 합침.

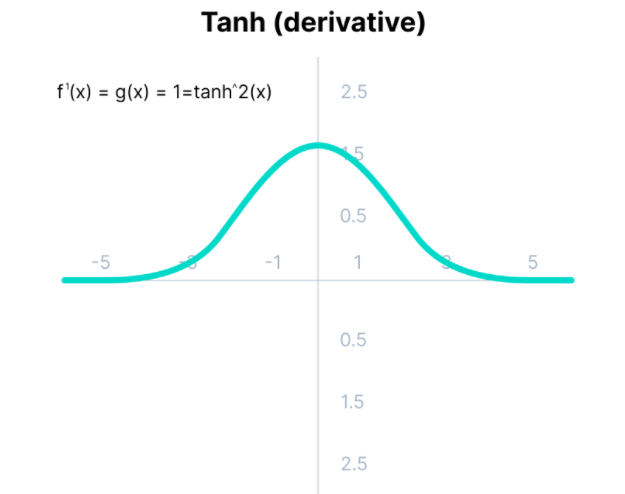
- Vanishing Gradient 를 해결하기 위해 relu 를 사용한다.

- sigmoid, tanh의 미분 함수로 0.25/0.5 보다 작은 값이 중첩되어 곱해지면서 미분값이 0에 수렴하게 된다.

5. Activation(활성화 함수)

5.1. Loss Function

- softmax
# w * x + w * x + w * x + ... + + b
y1 = 2 ** 200
y2 = 2 ** 20
y3 = 2 ** -10
S = y1 + y2 + y3
y11 = y1 / S
y22 = y2 / S
y33 = y3 / S
print(y11, y22, y33)
# 결과
1.0 6.525304467998525e-55 6.077163357286271e-64
출처: AI Hub 교육과정 - WEB+AI (위 내용이 문제가 된다면 댓글에 남겨주세요. 바로 삭제조치하도록 하겠습니다.)
'Programming 개발은 구글로 > 기타 정보' 카테고리의 다른 글
| [WEB+AI] 30일차 딥러닝 + RNN (0) | 2024.11.22 |
|---|---|
| [WEB+AI] 29일차 딥러닝 이미지 학습 및 LeNet5 (1) | 2024.11.21 |
| [WEB+AI] 27일차 딥러닝 1/2 (0) | 2024.11.19 |
| [WEB+AI] 26일차 Orange 3 복습 (0) | 2024.11.18 |
| [WEB+AI] 25일차 Orange 3 통계 - Logistic Regression, Tree 모델 (6) | 2024.11.15 |




댓글