딥러닝 텐서플로우
강사: 이숙번님
1. 딥러닝

- 지도학습: 정답이 있는(종속변수가 있음) 상태에서 학습
- 비지도학습: 정답이 없는 상태에서 학습
- 강화학습: 환경이 있음.

1.1. 레모네이드 판매량 예측하기
import pandas as pd
import tensorflow as tf
# 1. 데이터를 준비합니다.
레모네이드 = pd.read_csv('lemonade.csv')
x_train = df[['온도']]
y_train = df[['판매량']]
print(x_train.shape, y_train.shape)
# 2. 모델의 구조를 만듭니다.
X = tf.keras.layers.Input(shape=[1])
Y = tf.keras.layers.Dense(1)(X)
model = tf.keras.models.Model(X, Y)
model.compile(loss='mse')
# 3. 데이터로 모델을 학습(fit)합니다.
model.fit(x_train, y_train, epochs=1000)
# 4. 모델을 이용합니다.
model.predict(tf.constant([[15]]))
- 모델은 단순 선형 회귀 형태입니다:
Y = W⋅X+b
- X: 입력 (온도).
- W: 가중치.
- b: 편향.
- Y: 출력 (판매량).
- Dense(1)은 출력층의 뉴런 수가 1개라는 뜻입니다.
- 손실 함수로 mse(Mean Squared Error)를 사용: 오차 제곱 평균을 최소화하여 모델의 예측값이 실제 값과 가까워지도록 학습합니다.
- 모델을 학습시킬 때:
- 독립 변수 (온도)를 입력 데이터로 사용.
- 종속 변수 (판매량)을 실제 레이블로 사용.
- epochs=1000은 학습을 1000번 반복한다는 뜻입니다.
- 이 과정에서 모델은 W와 b를 최적화하여 예측이 실제 데이터와 가까워지도록 조정합니다.
- 학습이 완료된 후, 독립 변수(온도)를 입력으로 넣어 판매량을 예측합니다.
- 결과는 각 온도 값에 대해 학습된 모델이 계산한 예측 판매량입니다.
# 결과
- 학습 중 출력:
- 모델이 매 epoch마다 손실(mse) 값을 출력합니다.
- 손실 값은 점차 감소하며, 이는 모델이 점점 데이터를 잘 학습하고 있다는 의미입니다.
- 예측 결과 출력:
- model.predict(독립)은 입력 데이터(온도)에 대한 예측값(판매량)을 반환합니다.
- 예: [[50], [60], [70]] 같은 온도 입력에 대해 [[200], [250], [300]] 같은 판매량 예측값이 나옵니다.
레모네이드[['온도', '판매량']] # 필드를 여러개 지정해서 DataFrame(표) 형태로 가져오기. [[1, 1], [2, 2], [3, 3], [4, 4], [5, 5], [6, 6]]
레모네이드['온도'] # 필드를 하나 지정해서 Series(리스트) 형태로 가져오기. [1, 2, 3, 4, 5, 6]
# 레모네이드['온도', '판매량'] # 필드를 하나 지정해서 리스트 형태로 가져오기. - 이렇게 쓰면 에러. 대괄호 한번은 필드 하나만 지정 가능
model.get_weights()
# 결과
[array([[1.967355]], dtype=float32), array([0.7503077], dtype=float32)]
# 판매량 = 1.967355 * 온도 + 0.7503077
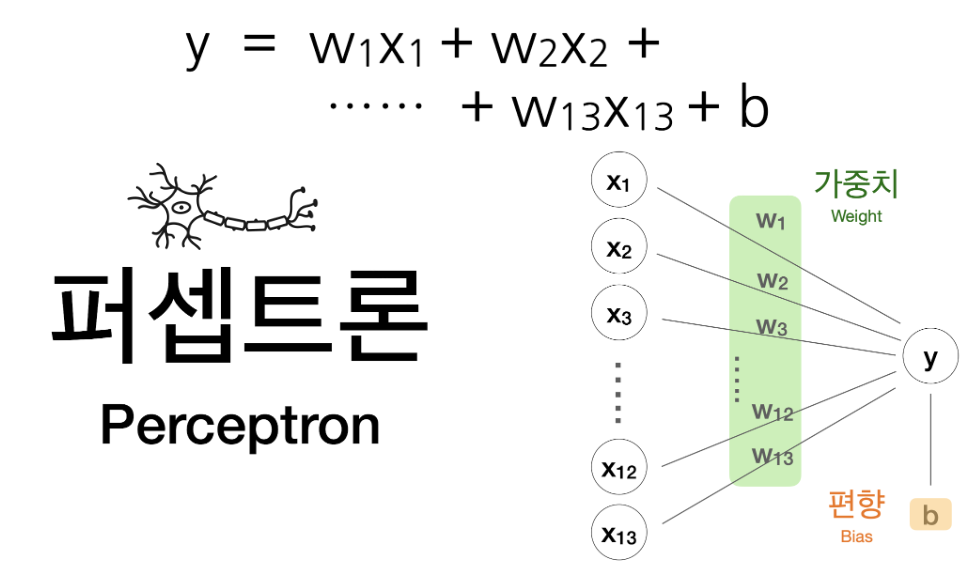
1.2. 보스턴 집값 예측하기
import pandas as pd
import tensorflow as tf
url = 'https://raw.githubusercontent.com/blackdew/tensorflow1/refs/heads/master/csv/boston.csv'
df = pd.read_csv(url)
x_train = df[['crim', 'zn', 'indus', 'chas', 'nox', 'rm', 'age', 'dis', 'rad', 'tax',
'ptratio', 'b', 'lstat']]
y_train = df[['medv']]
print(df.shape)
print(x_train, y_train)
X = tf.keras.layers.Input(shape=[13])
Y = tf.keras.layers.Dense(1)(X)
model = tf.keras.models.Model(X, Y)
model.compile(loss='mse')
model.summary()
model.fit(x_train, y_train, epochs=1000)
df_sample = df.sample(5)
model.predict(df_sample.iloc[:, :13])

b: 기본값이나 초기값, 그래프의 위치를 결정함.
만약 b가 없다면:
- 모든 직선은 원점(0, 0)을 지나야 합니다.
- 하지만 대부분의 데이터는 원점을 지나지 않으므로 b가 필요합니다.

1.3. 아이리스 분류하기
1.3.1. 원핫인코딩

- 범주형 데이터 유형을 처리하는 가장 유용한 방법

import pandas as pd
url = 'https://raw.githubusercontent.com/blackdew/tensorflow1/refs/heads/master/csv/iris.csv'
df = pd.read_csv(url)
df_onehot = pd.get_dummies(df)

import pandas as pd
url = "https://raw.githubusercontent.com/blackdew/tensorflow1/refs/heads/master/csv/iris.csv"
df = pd.read_csv(url)
df_onehot = pd.get_dummies(df)
x_train = df_onehot[['꽃잎길이', '꽃잎폭', '꽃받침길이', '꽃받침폭']]
y_train = df_onehot[['품종_setosa', '품종_versicolor', '품종_virginica']]
print(df_onehot.shape)
print(x_train.shape, y_train.shape)
X = tf.keras.Input(shape=[4])
Y = tf.keras.layers.Dense(3, activation="softmax")(X)
model = tf.keras.Model(X, Y)
model.compile(loss="categorical_crossentropy", metrics=['accuracy'])
model.summary()
model.fit(x_train, y_train, epochs=1000)
df_sample = df.sample(5)
model.predict(df_sample.iloc[:, :4])
# 결과
...
Epoch 1000/1000
5/5 ━━━━━━━━━━━━━━━━━━━━ 0s 5ms/step - accuracy: 0.9720 - loss: 0.1604
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 93ms/step
array([[2.40786831e-04, 7.86004663e-01, 2.13754579e-01],
[1.03812345e-05, 3.38136911e-01, 6.61852717e-01],
[9.99131382e-01, 8.68640433e-04, 5.44598215e-08],
[6.76493926e-07, 1.92442536e-01, 8.07556808e-01],
[1.48948713e-03, 8.81887913e-01, 1.16622604e-01]], dtype=float32)
df_sample['품종']

출처: AI Hub 교육과정 - WEB+AI (위 내용이 문제가 된다면 댓글에 남겨주세요. 바로 삭제조치하도록 하겠습니다.)
'Programming 개발은 구글로 > 기타 정보' 카테고리의 다른 글
| [WEB+AI] 29일차 딥러닝 이미지 학습 및 LeNet5 (1) | 2024.11.21 |
|---|---|
| [WEB+AI] 28일차 딥러닝 2/2 (0) | 2024.11.20 |
| [WEB+AI] 26일차 Orange 3 복습 (0) | 2024.11.18 |
| [WEB+AI] 25일차 Orange 3 통계 - Logistic Regression, Tree 모델 (6) | 2024.11.15 |
| [WEB+AI] 24일차 오렌지 3 통계 3/3 (1) | 2024.11.15 |




댓글