파이썬 데이터 분석
강사: 이주화님
1. pandas 라이브러리
: 테이블형 데이트를 다룰 수 있는 다양한 기능을 가진 라이브러리
- CSV(Comma-Separated Values): 데이터를 쉼표(콤마)로 구분하여 저장하는 파일 형식
참고로, CSV 파일에서 내용이 빠져 있는 데이터를 결측치 또는 누락값(missing value)이라고 합니다.
2. pandas 라이브러리 import
import pandas as pd
파일 업로드 및 가져오기
import pandas as pd
data = pd.read_csv('/content/sample_data/titanic.csv')
# colab에서 file explorer에서 해당 파일 경로 복사 후 read_csv 경로에 입력
3. ChatGPT 문의 사항
아래 데이터셋을 분석하려고 해
데이터셋: https://www.kaggle.com/datasets/zain280/titanic-data-set
각 컬럼의 의미를 알려줘
난 이제부터 코랩에서 파이썬으로 데이터분석을 할꺼야.
위 데이터를 읽어오고 데이터를 확인하기 위한 코드를 작성해줘
- 데이터 확인 및 탐색
- df.info()는 데이터셋의 컬럼별 데이터 타입, 결측치 여부 등을 확인하는 데 사용됩니다.
- df.head()는 데이터셋의 상위 5개의 데이터를 확인할 수 있습니다. 데이터를 미리 살펴보며 전체적인 구조를 파악할 수 있습니다.
- 데이터의 기본 통계량을 확인하려면 df.describe()를 사용하세요.
from google.colab import files
import pandas as pd
# 파일 업로드
uploaded = files.upload()
# 데이터셋 읽기
df = pd.read_csv('titanic.csv')
# 데이터셋 정보 확인
df.info()
# 데이터셋 상위 5개 행 미리보기
df.head()
# 데이터의 기본 통계량을 확인
df.describe()
# 중복된 행 여부 확인
duplicates = df.duplicated().sum()
print(f"중복된 행의 갯수: {duplicates}")
import missingno as msno
import matplotlib.pyplot as plt
# 결측치 시각화
msno.matrix(df)
plt.show()
# 다른 시각화 예시 (바 차트)
msno.bar(df)
plt.show()
- 컬럼의 결측시를 중앙값(median)으로 채우기
Age 컬럼의 결측치를 중앙값(median)으로 채우는 코드는 다음과 같습니다:
... # 데이터셋 로드 생략
# Age 컬럼의 중앙값 계산
age_median = df['Age'].median()
# Age 컬럼의 결측치를 중앙값으로 채우기
df['Age'].fillna(age_median, inplace=True) # 대입으로 변경(Warning 해결) -> df['Age'] = df['Age'].fillna(age_median)
# 변경된 데이터 확인 (결측치가 없는지 확인)
print("Age 컬럼의 결측치 개수:", df['Age'].isnull().sum())
# .isnull(): 선택한 컬럼에서 결측치(null) 여부 확인
# .sum(): 배열에서 True의 총 개수
- 최빈값(Mode)은 데이터에서 가장 자주 나타나는 값을 의미합니다.
예를 들어, 1, 2, 2, 3, 4라는 데이터가 있다면 숫자 2가 두 번 나타나므로 이 데이터의 최빈값은 2입니다.
most_frequent_value = df['Cabin'].mode()[0]
# 결측치를 최빈 값으로 채우기
df['Cabin'] = df['Cabin'].fillna(most_frequent_value)
# 결과 출력
print(df.isnull().sum())
# Ticket 컬럼 삭제
df = df.drop('Ticket', axis=1)
# 결과 확인
print(df.columns)
# 두 가지 방법으로 'Ticket' 컬럼 제거
df1 = df.drop(columns=['Ticket']) # 방법 1
df2 = df.drop('Ticket', axis=1) # 방법 2
import seaborn as sns
import matplotlib.pyplot as plt
# 객실 등급별 탑승객 수를 바차트로 그리기
plt.figure(figsize=(10, 6))
sns.countplot(x='Pclass', data=df, palette='Set2')
plt.title('Passengers by Pclass')
plt.xlabel('Pclass')
plt.ylabel('Count')
# 생존 여부에 따른 객실 등급별 탑승객 수를 바차트로 그리기
plt.figure(figsize=(10, 6))
sns.countplot(x='Pclass', hue='Survived', data=df, palette='Set1')
plt.title('Survival by Pclass')
plt.xlabel('Pclass')
plt.ylabel('Count')
plt.legend(title='Survived', loc='upper right')
plt.show()
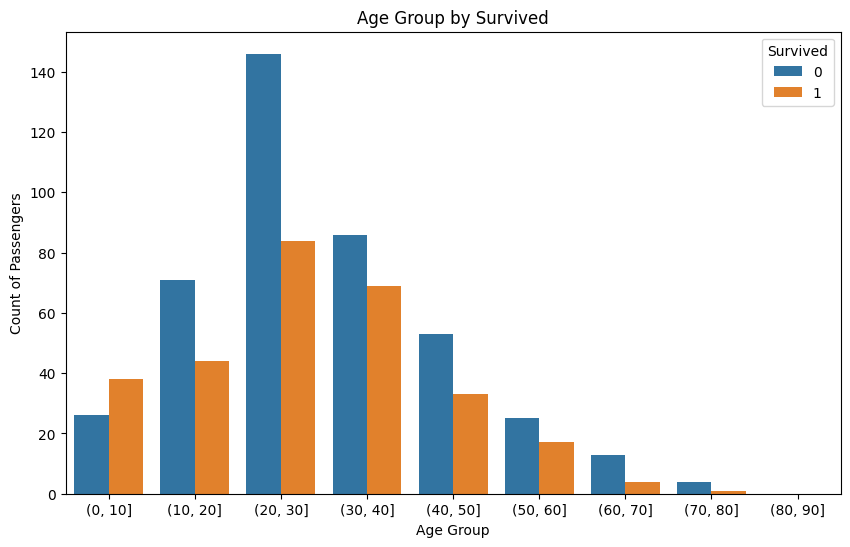
- 많아서 촘촘한 바차트를 10단위로 나뉘어서 표시
# 나이를 10단위로 묶기
df['AgeGroup'] = pd.cut(df['Age'], bins=range(0, 91, 10))
sns.countplot(x='AgeGroup', hue='Survived', data=df)
plt.title('Age Group by Survived')
plt.xlabel('Age Group')
plt.ylabel('Count of Passengers')
plt.show()
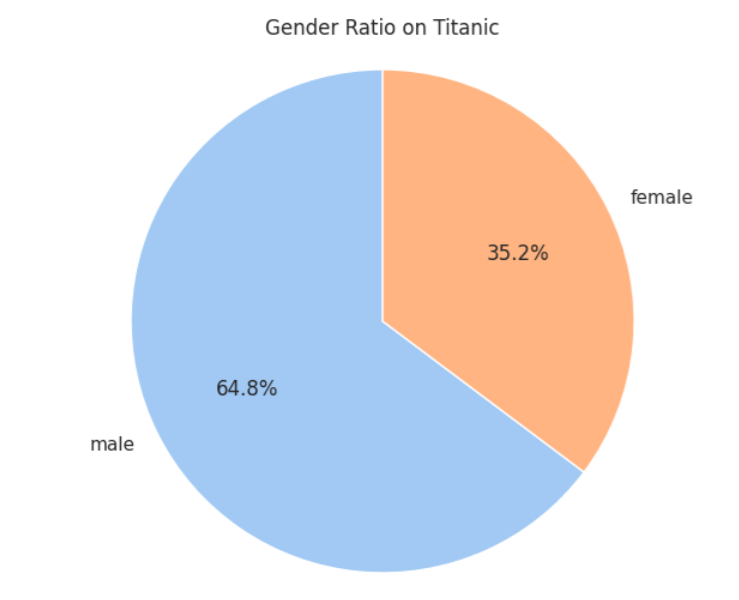
- 원차트로 그리기
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 데이터프레임 읽기
data = pd.read_csv('/content/sample_data/titanic.csv')
# 성별 비율 계산
gender_counts = df['Sex'].value_counts()
# Seaborn 스타일 적용 - 이건 필요한 건가?
sns.set(style='whitegrid')
# 원차트 그리기
plt.figure(figsize=(8, 6))
plt.pie(gender_counts, labels=gender_counts.index, autopct='%1.1f%%', startangle=90, colors=sns.color_palette("pastel"))
plt.title('Gender Ratio on Titanic')
plt.axis('equal') # 원이 동그랗게 보이도록 설정
plt.show()
- URL 에서 데이터를 읽어오기
# Titanic 데이터셋 로드
url = "https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv"
df = pd.read_csv(url)
- csv 파일 다운로드 후 zip 파일 압축 해제하여 파일 읽기
#파일 다운로드
!kaggle datasets download -d kreeshrajani/used-car-price-dataset
import zipfile
import pandas as pd
# 다운로드한 zip 파일 압축 해제
with zipfile.ZipFile('/content/used-car-price-dataset.zip', 'r') as zip_ref:
zip_ref.extractall()
# CSV 파일 읽기 (파일 이름이 다를 수 있으니 확인 후 수정)
df = pd.read_csv('used_car_dataset.csv') # 실제 CSV 파일 이름으로 변경
# 데이터 확인
print(df.head())
출처: AI Hub 교육과정 - WEB+AI (위 내용이 문제가 된다면 댓글에 남겨주세요. 바로 삭제조치하도록 하겠습니다.)
'Programming 개발은 구글로 > 기타 정보' 카테고리의 다른 글
| [WEB+AI] 9일차 OpenAI API 이해와 활용 (3) | 2024.10.24 |
|---|---|
| [WEB+AI] 8일차 파이썬 데이터 분석(추가 내용) (0) | 2024.10.24 |
| [WEB+AI] 7일차 Gradio + PostgreSQL로 메모장 만들기 (2) | 2024.10.22 |
| [WEB+AI] 5일차 Database(PostgreSQL) (3) | 2024.10.22 |
| [WEB+AI] 6일차 복습 (4) | 2024.10.22 |




댓글