티처블 머신을 활용한 AI 웹페이지 만들기
강사: 이주화님
1. 티처블 머신
홈페이지: https://teachablemachine.withgoogle.com
- 티처블 머신은 구글에서 제공하는 머신러닝 학습 도구
- 누구나 머신러닝 모델을 쉽고 빠르게 만들 수 있도록 제작된 웹 기반 도구
- 티처블 머신을 사용해 이미지, 사운드, 포즈를 학습할 수 있음.
1.1. 이미지 크롤링
- bing-image-downloader 라이브러리 설치
!pip install bing-image-downloader
1.2. 이미지 가져오기
from bing_image_downloader import downloader
# bing_image_downloader 모듈의 downloader.download 함수를 사용하여 Bing 이미지 검색 결과를 다운로드
def download_images(keyword, limit):
downloader.download(keyword, limit=limit, output_dir='images', adult_filter_off=True, force_replace=False)
# keyword 매개변수: 검색어
# limit 매개변수: 다운로드할 이미지 개수
# output_dir 매개변수: 이미지를 저장할 디렉토리를 지정
# adult_filter_off 매개변수: True로 설정하면, 성인 콘텐츠가 필터링되지 않음. (필터링을 적용하려면 False로 설정)
# force_replace 매개변수: True로 설정하면, 동일한 이름의 이미지 파일이 이미 존재하는 경우에도 강제로 덮어씀.
keyword = input("이미지 검색어를 입력하세요: ")
limit = int(input("다운로드할 이미지 개수를 입력하세요: "))
download_images(keyword, limit)
- 실행 결과
이미지 검색어를 입력하세요: 삼성라이온즈 강민호
다운로드할 이미지 개수를 입력하세요: 2

1.3. 이미지 압축
import shutil
# shutil: 파일 및 폴더를 복사, 이동, 삭제, 압축하는 기능 포함된 모듈
def compress_folder(folder_path, output_path):
shutil.make_archive(output_path, 'zip', folder_path)
# 이미지 저장 폴더 압축
folder_path = "images"
output_path = "images"
compress_folder(folder_path, output_path)
# folder_path 압축하려는 폴더의 경로
# output_path: 압축 파일을 저장할 경로 및 파일 이름
1.4. 티처블 머신 실행

- 각각의 클래스에 이미지를 업로드 한 후 학습을 시킴.
- Webcam을 실행하면 유사한 이미지의 확률을 보여줌.
1.5. Tensorfolw - Keras로 모델 내보내기

※ Colab에서 사용할 수 있게 tensorflow 버전 다운그레이드
!pip install tensorflow==2.12.0
- 버전 확인
import tensorflow as tf
print(tf.__version__)
- keras 코드를 Colab에 복사 후 경로 설정 및 파일 업로드 후 실행

from keras.models import load_model # TensorFlow is required for Keras to work
from PIL import Image, ImageOps # Install pillow instead of PIL
import numpy as np
# Disable scientific notation for clarity
np.set_printoptions(suppress=True)
# Load the model
model = load_model("/content/sample_data/keras_model.h5", compile=False)
# Load the labels
class_names = open("/content/sample_data/labels.txt", "r").readlines()
# Create the array of the right shape to feed into the keras model
# The 'length' or number of images you can put into the array is
# determined by the first position in the shape tuple, in this case 1
data = np.ndarray(shape=(1, 224, 224, 3), dtype=np.float32)
# Replace this with the path to your image
image = Image.open("/content/sample_data/Image_5.jpg").convert("RGB")
# resizing the image to be at least 224x224 and then cropping from the center
size = (224, 224)
image = ImageOps.fit(image, size, Image.Resampling.LANCZOS)
# turn the image into a numpy array
image_array = np.asarray(image)
# Normalize the image
normalized_image_array = (image_array.astype(np.float32) / 127.5) - 1
# Load the image into the array
data[0] = normalized_image_array
# Predicts the model
prediction = model.predict(data)
index = np.argmax(prediction)
class_name = class_names[index]
confidence_score = prediction[0][index]
# Print prediction and confidence score
print("Class:", class_name[2:], end="")
print("Confidence Score:", confidence_score)
- 실행 결과

1.6. Tensorflow.js - tm-my-image-model.zip 파일 다운로드

- Vscode Open 후 Javascript 복사 코드 추가
- <body></body> 사이에 복사한 코드 추가
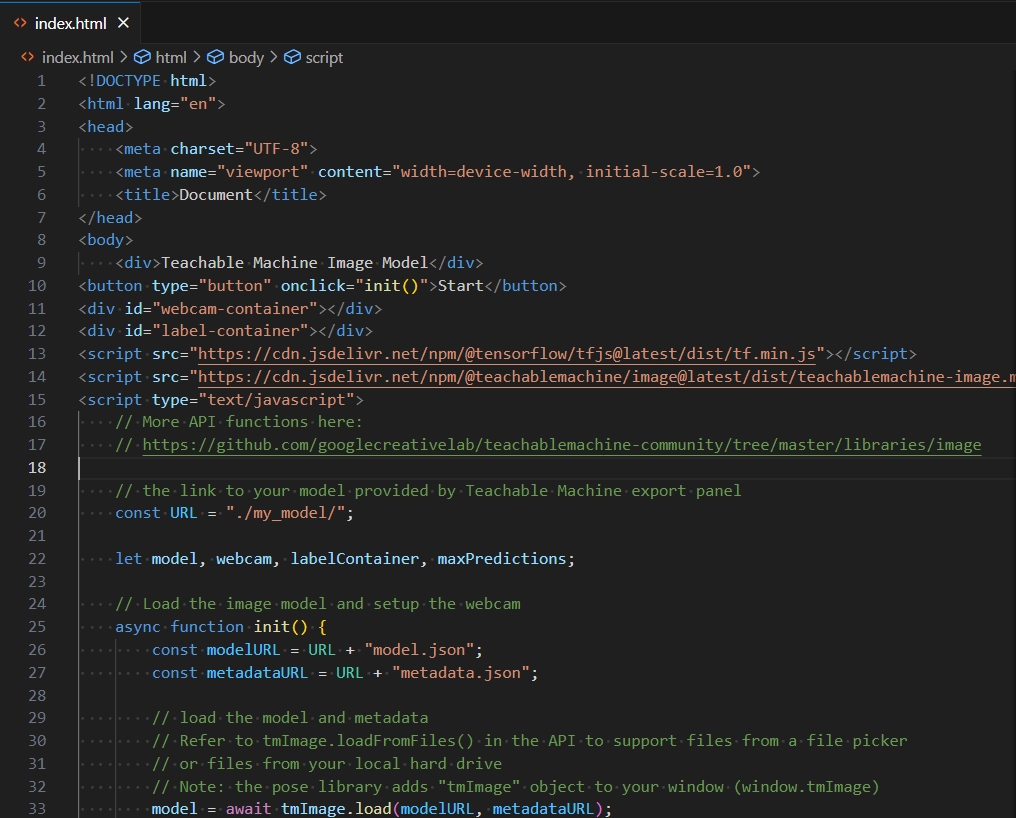
- 다운로드 받은 tm-my-image-model에 있는 3개의 파일을 my_model 폴더를 생성 후 업로드함.


- 오른쪽 마우스 눌러서 Open with Live Server 실행

- 실행화면

1.7. 비교 예측한 결과로 웹페이지 이동(1.6. 코드 수정)

- awit 키워드를 사용하여 predict 비동기 함수를 정의함.
- model.predict() 메서드를 호출하여 머신러닝 모델이 webcam.canvas에서 가져온 이미지 데이터를 바탕으로 예측을 수행함
- awit 키워드를 사용하여 예측이 완료 될 때까지 기다린 후 결과를 prdiction 변수에 저장함.
- prediction[0].probability가 0.60보다 큰 경우 True가 됨.
- toFixed(2): 확률값을 소수점 둘째 자리까지 반올림함.
- html 생성

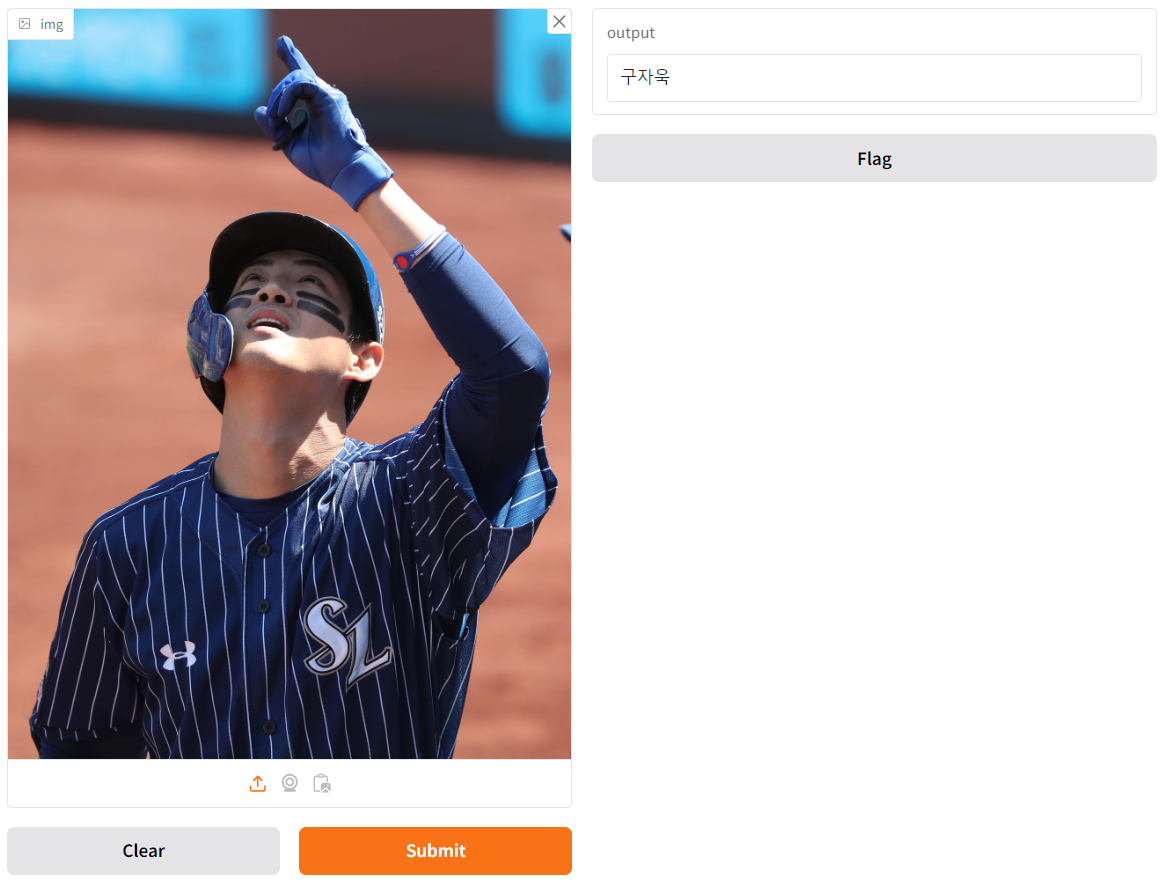
- 실행 결과

- 구자욱 선수를 닮지는 않았지만, 표본이 적다보니... ^^
1.8. Gradio를 이용하여 이미지 유사도 확인하기
import gradio as gr
import numpy as np
from PIL import Image, ImageOps # 추가된 부분
# 분류할 클래스 리스트
classes = ['강민호', '구자욱', '이재현']
def predict_image(img):
data = np.ndarray(shape=(1, 224, 224, 3), dtype=np.float32)
# 이미지 변환 및 전처리
image = Image.fromarray(img).convert("RGB") # 수정된 부분
size = (224, 224)
image = ImageOps.fit(image, size, Image.Resampling.LANCZOS)
image_array = np.asarray(image)
# 이미지 정규화
normalized_image_array = (image_array.astype(np.float32) / 127.5) - 1
data[0] = normalized_image_array
# 모델 예측
prediction = model.predict(data)
max_index = np.argmax(prediction) # 확률이 가장 높은 인덱스
return classes[max_index]
# Gradio 앱 인터페이스 설정
app = gr.Interface(fn=predict_image, inputs="image", outputs="text")
app.launch(share=True, debug=True)
- data 배열: (1, 224, 224, 3) 크기의 배열을 만들고 데이터 타입을 float32로 설정합니다.
- 이 배열은 모델에 입력될 이미지를 저장합니다.
- (1, 224, 224, 3)는 배치 크기 1, 너비와 높이 각각 224 픽셀, 3은 RGB 채널을 나타냅니다.
- Image.fromarray(img).convert("RGB"):
- Gradio에서 제공하는 이미지는 *NumPy 배열 형식으로 입력됩니다. 따라서 Image.fromarray(img)로 배열을 이미지 객체로 변환합니다.
- .convert("RGB")를 통해 이미지를 RGB 형식으로 변환하여 일관된 색상 공간을 유지합니다.
- ImageOps.fit(image, size, Image.Resampling.LANCZOS):
- 이미지를 (224, 224) 크기로 조정합니다. Image. Resampling.LANCZOS는 고해상도 이미지를 낮은 해상도로 변환할 때 주로 사용되는 *보간 방법으로, 이미지 품질을 최대로 유지합니다.
- np.asarray(image):
- 크기 조정된 이미지를 NumPy 배열 형식으로 변환하여 후속 처리와 모델 입력에 사용할 수 있게 합니다.
* NumPy 배열 형식
: Python의 NumPy 라이브러리가 제공하는 다차원 배열 (multi-dimensional array) 형식으로 행렬 또는 텐서 형태로 데이터를 저장됨.
# NumPy 배열 예제
# 1차원 배열 (벡터)
array_1d = np.array([1, 2, 3, 4])
print(array_1d) # 출력: [1 2 3 4]
# 2차원 배열 (행렬)
array_2d = np.array([[1, 2, 3], [4, 5, 6]])
print(array_2d)
# 출력:
# [[1 2 3]
# [4 5 6]]
* 보간 방법
: 보간은 두 개의 데이터 지점 사이에 값을 예측하여 새로운 데이터 지점을 만들어 내는 작업을 의미함.
특히 이미지 보간은 이미지의 크기를 변경할 때 발생하는 빈 픽셀 값을 예측하여 채우는 과정임.
정규화: image_array.astype(np.float32) / 127.5) - 1는 이미지 픽셀 값을 -1에서 1 사이로 정규화합니다.
- 일반적으로 머신러닝 모델은 정규화된 값을 사용해 학습됩니다.
- 정규화된 이미지를 data[0]에 저장하여 모델의 입력 형태로 만듭니다.
- 실행 결과
2. 머신러닝
2.1. 개요
- 데이터로부터 결과를 찾는 것이 아닌 주어진 데이터로부터 규칙성을 찾는 것이 목표로 기계가 규칙성을 찾도록 학습하는 것
| Y = w * X + b X 가 주어졌을 때, Y를 만족하는 w와 b를 찾아내는 것 |
- X : 입력 값 (Feature)
- Y : 출력 값 (Label)
- w : 가중치 (Weight)
- b : 편향 (Bias)
2.2. 머신러닝 단계
- 문제 정의
: 해결해야 할 문제 분석
- 데이터 수집
: 머신러닝에 활용할 학습 데이터 수집
- 데이터 전처리
: 데이터 형식 변형 및 비어 있는 값 채우기, 연관 데이터 추가, 삭제
- 알고리즘 / 모델 선택
: 문제 해결을 위해 알고리즘 / 모델 선택
- 학습
: 선택한 알고리즘 / 모델에 학습 데이터 입력하여 학습
- 평가
: 새로운 데이터에 대한 예측, 머신러닝 모델의 성능 평가
2.2.1. 머신러닝의 유형
- 회귀(Regrssion)
- 학습 데이터에 부합하는 출력 값을 찾아주는 함수를 찾아내는 방법 (e.g., 사람의 몸무게를 기반으로 키 예측)

- 분류(Classification)
- 정해진 카테고리 내에서 입력된 값이 어느 카테고리에 속하는지 찾아내는 방법 (e.g., 개, 고양이 분류)

- 군집화(Clustering)
- 유사성이 높은 데이터들을 동일한 그룹으로 분류하고 서로 다른 군집들이 상이성을 가지도록 그룹화하는 방법 (e.g., 소비 수준에 따른 고객군 군집화)

- 이상값 감지(Anomaly Detection)
- 매우 적은 비율로 발생하는 비정상적인 데이터를 검출하는 방법 (e.g., 금융 사기 감지)

- 강화(Reinforcement)
- 에이전트가 현 상태에서 선택 가능한 다양한 행동 중 보상을 최대화하는 방향으로 선택하는 방법 (e.g., 알파고)
2.2.2. 머신러닝의 종류
- 지도학습 (Supervised learning)
- 정답이 있는 데이터를 활용해 데이터를 학습하는 방법
- 입력 값(X data, Feature)과 입력값에 대한 결과 값(Y data, Lable)이 주어진 상태로 학습
- 비지도학습 (Unsupervised learning)
- 정답이 없는 데이터를 학습하여 결과 값을 예측하는 방법
- 입력 값(X data, Feature)은 주어지지만 입력값에 대한 결과 값(Y data, Lable)은 주어지지 않은 상태로 학습
- 강화학습 (Reinforcement Learning)
- 결과 값(Y data, Lable)이 주어지지 않은 상태로 경험에 기반하여 시행착오와 보상을 통해 학습
출처: AI Hub 교육과정 - WEB+AI (위 내용이 문제가 된다면 댓글에 남겨주세요. 바로 삭제조치하도록 하겠습니다.)
'Programming 개발은 구글로 > 기타 정보' 카테고리의 다른 글
| [WEB+AI] 19일차 사생대회 + 파이썬 (2) | 2024.11.07 |
|---|---|
| [WEB+AI] 18일차 Web+AI 사생대회 (6) | 2024.11.06 |
| [WEB+AI] 16일차 Gradio 복습 (6) | 2024.11.04 |
| [WEB+AI] 15일차 RAG 앱 구현 (2) | 2024.11.01 |
| [WEB+AI] 14일차 Embedding(임베딩) + Python (0) | 2024.10.31 |




댓글