대언어모델 시대
강사: 생활코딩 이고잉님
🟦 (본격적인 수업 진행 전) 문의 사항


위의 표와 단어 중에서 본인이 아는 것을 확인해보세요.
전 Transfomer, GPT, Deep Learning, Parameter, RLHF, Metric, Token 만 알고 있었습니다. ㅠㅠ
개인적인 사정으로 교육을 끝까지 참석하지 못하였습니다.
강의 자료를 참조해서 계속 업데이트를 하도록 하겠습니다.
LLM(Large Language Model)
: 대규모 언어 모델은 방대한 양의 데이터로 사전 학습된 초대형 딥러닝 모델입니다.
BERT(Bidrectional Encoder Representations from transformers)
: 구글에서 만든 언어 모델로 GPT와 비슷한 리소스로 가지고 있으면서 GPT와 다른 점은 이해에는 초점을 둠.
인코더의 크기를 극적으로 키움, 병렬처리로 빠르게 동작함.
GPT(Generative Pre-trained Transformer)
: 디코더(말하기)만 가지고 모델의 크기를 키웠음.
NLP: 인간의 언어를 이해하기 위한 자연어
RNN(Recurrent Neural Network)
:

LSTM(Long Short-Term Memory)
: 중요한 기억들을 장기 기억으로 빼고, 사소한 기억들을 단기 기억으로 보는 RNN

Perceptron
: 1957년 Frank Rosenblatt, 최초의 기계적 구현, 최초의 학습적 모델
인공신경 하나를 Peceptron으로 하고 자연신경을 뉴런으로 지칭하여 1:1 대칭하는 모델
MLP
: 여러 개의 Pcrceptron을 묶은 심층 신경망의 이론 제시

Token( 토큰)
: 뜻을 지니는 가장 작은 단위의 단어 조각
토큰화(tokenize)
1. 토큰화 방법
- 의미를 지니는 가장 최소 단위를 찾는다.
2. 토큰화 예시
- 계획이 있다.
-> '계획이', '_다'
3. 각 토큰에 해당하는 숫자 번호로 변경
- [4744, 10635, 148]
Knowledge Cutoff
: 학습의 시간이 오래되면 최신 자료를 알 수 없으므로, 검색한 정보를 기존의 데이터와 합쳐서 제공
H100
: Meta에서 llama를 학습시킬 때 컴퓨터 이름
GQA
: 사람처럼 대화를 느낄 수 있음.
MMLU(Massive Multitask Language Understanding)
: 57개의 주제도 된 15908개의 4지선다형 문제
Shots
: 질문의 샘플을 몇 개인지? 즉 Shots 5개란 샘플 5개를 보여주고 질문을 했다는 뜻
Metric
: 평가하는 지표(점수 계산 방식)
Meta의 Llama 3.1 다국어 대형 언어 모델(LLM, Large Language, Model) 컬렉션은
8B, 70B, 405B 크기의 사전 학습 및 명령어 튜닝된 생성 모델들의 모음입니다.
Llama 3.1 명령어 튜닝된 텍스트 전용 모델(8B, 70B, 405B)은 다국어 대화 사용 사례에 최적화되어 있습니다.
지원 언어: 영어, 독일어, 프랑스어, 이탈리아어, 포르투갈어, 힌디어, 스페인어, 태국어.
Llama 3.1 모델군. 토큰 수는 사전 학습 데이터만을 나타냅니다.
모든 모델 버전은 향상된 추론 확장성을 위해 GQA을 사용합니다.
모델 출시일: 2024년 7월 23일
상태: 이 모델은 오프라인 데이터셋으로 학습된 정적 모델입니다.
향후 튜닝된 모델의 새로운 버전은 커뮤니티 피드백을 통해 모델 안전성이 개선됨에 따라 출시될 예정입니다.
라이선스: Llama 3.1 커뮤니티 라이선스라는 맞춤형 상업 라이선스가 제공
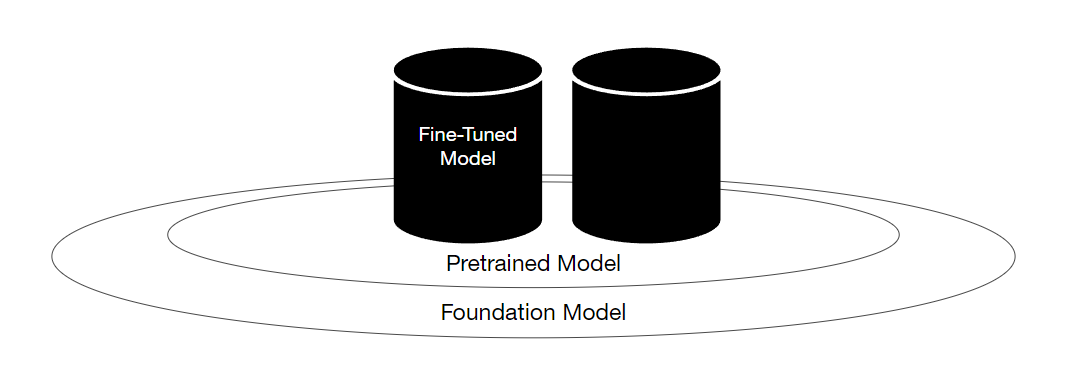
🟩 모델 아키텍처
: Llama 3.1은 최적화된 트랜스포머 아키텍처를 사용하는 *auto-regressive 언어 모델입니다.
튜닝된 버전은 유용성과 안전성에 대한 인간의 선호도에 맞추기 위해 *supervised fine-tuning(SFT)과 *reinforcement learning with human feedback(RLHF)를 사용합니다.
훈련 데이터
개요: Llama 3.1은 공개적으로 이용 가능한 소스로부터 약 15조 개의 토큰 데이터를 사용해 사전 훈련되었습니다.
미세 조정 데이터에는 공개적으로 이용 가능한 명령어 데이터셋과 2,500만 개 이상의 합성 생성 예제가 포함됩니다.
데이터 최신성: 사전 훈련 데이터는 2023년 12월을 기준으로 최신 데이터입니다.
*auto-regressive
: 자가(스스로) 회귀는 자기 자신을 입력 데이터로 하여 스스로를 예측하는 모델입니다.
- 현재 시점까지 생성한 output을 사용하여 다음 시점의 output에 대한 예측을 수행합니다.
- 현 시점의 데이터는 이전 시점의 모든 데이터와 dependency를 가지고 있습니다.
*supervised fine-tuning(SFT)
: Lable이 지정된 데이터를 사용하여 LLM을 훈련하는 미세 조정 유형입니다.
SFT는 LLM을 Fine-tunning 하는 비교적 간단하고 효율적인 방법입니다.
*reinforcement learning with human feedback(RLHF)
: LLM을 훈련하기 위해 인간의 피드백을 사용하는 Fine-tuning의 한 종류입니다.
인간의 피드백은 설문조사(suvey), 인터뷰, 사용자 연구 등 다양한 방법으로 수집할 수 있습니다.
왜이리 말이 어려운지?
출처: AI Hub 교육과정 - WEB+AI (위 내용이 문제가 된다면 댓글에 남겨주세요. 바로 삭제조치하도록 하겠습니다.)
'Programming 개발은 구글로 > 기타 정보' 카테고리의 다른 글
| [WEB+AI] 12일차 Chat AI + GPT (3) | 2024.10.29 |
|---|---|
| [WEB+AI] 11일차 복습 (0) | 2024.10.28 |
| [WEB+AI] 9일차 OpenAI API 이해와 활용 (3) | 2024.10.24 |
| [WEB+AI] 8일차 파이썬 데이터 분석(추가 내용) (0) | 2024.10.24 |
| [WEB+AI] 8일차 파이썬 데이터 분석 (3) | 2024.10.23 |




댓글